-
Importing links from Telegram into your bookmarks manager
If you have ever sent links to yourself in Telegram in an attempt to bookmark it (like I sometimes do), or if you just want to extract all links that people have sent you and transfer them over to your bookmark manager, this post is for you. I was recently in this situation, and using a combination of Docker, a Telegram CLI tool, and a simple Python script, I was able to construct a Netscape Bookmarks file, which I successfully imported into my Pinboard account. This post describes the steps I followed, which I’m documenting here for posterity.
-
Enabling delayed hibernation on Arch Linux
This post describes how to enable (delayed) hibernation on Arch Linux. It is less for tutorial purposes and more to allow me to make a note to myself of one of the many crazy customizations I have done on Arch Linux in case I need to do them again someday.
The final goal is to be able to close your laptop lid, and let your system go into the suspended state, and if you don't open your lid for a couple of hours, automatically hibernate to disk.
Most of the instructions are taken from the Arch Wiki.
Assumptions:
- Your system is running with systemd and grub2
- Suspend already works without issues.
To enable hibernate:
This a condensed version of the instructions on the power management page on the arch wiki:
- The file
/sys/power/image_sizelists the size of the hibernate image created (in bytes). Since you're hibernating to your swap partition, make sure the size listed in this file is less than or equal to the size of your swap partition - You can find your swap partition by running
lsblkand seeing which partition has[SWAP]listed next to it. - Edit the variable
GRUB_CMDLINE_LINUX_DEFAULTin the file/etc/default/gruband appendresume=/dev/sda1to the string, assuming/dev/sda1is your swap partition. - Then run
grub-mkconfig -o /boot/grub/grub.cfgto regenerate yourgrub.cfg - Edit the variable
HOOKSin the file/etc/mkinitcpio.confto add theresumehook. Make sure you add it after theudevhook. NowHOOKSlooks like this:HOOKS="base udev resume autodetect modconf ..."
- Then run
mkinitcpio -p linuxto rebuild the initramfs.
That's it. Now your should be able to hibernate by typing in
systemctl hibernate.To enable delayed hibernation:
What this does is suspends your laptop when you close the lid. Then, if the laptop hasn't been used in 2 hours, it hibernates the laptop to disk.
- Create a file
/etc/systemd/system/suspend-to-hibernate.servicewith the following contents:[Unit] Description=Delayed hibernation trigger Documentation=https://bbs.archlinux.org/viewtopic.php?pid=1420279#p1420279 Documentation=https://wiki.archlinux.org/index.php/Power_management Before=suspend.target Conflicts=hibernate.target hybrid-suspend.target StopWhenUnneeded=true
-
Online collaborative whiteboard
After finding no single whiteboard with all the features I wanted, I decided to write one of my own. It uses enyojs, tornado, and redis and has lots of nice features. It is released under GPLv2
This is the GitHub page: http://anandtrex.github.com/collabdraw
The demo resides here: http://collab.cloudapp.net
Screenshot:
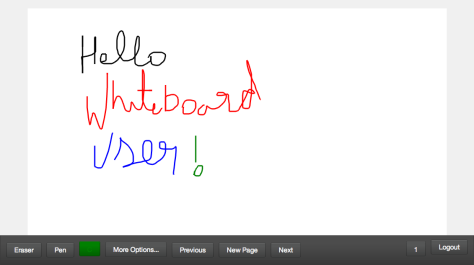
In short the features are:
- Works on most tablets out of the box, interface designed for touch interfaces
- Multiple rooms, pages for collaboration
- Take quick snapshots of the board
- Upload pdf and annotate on whiteboard
- Support for SSL, and authentication
- Fast, handles lots of users simultaneously
One of the goals of this project was to serve as an educational aid for online courses -- similar to what is used on sites like coursera.org or udacity.com, except instead of specialized and expensive hardware and software, all one would need is a cheap tablet and a server running this.
-
On the extinction of desktop applications.
Originally published on Aug 22nd, 2009:
I see people, well known people no less, claiming such ridiculous things on the internet, that I sometimes despair for humanity. It is a general rule that any wide sweeping claim that generalises things is very likely ridiculous. (yes I'm aware of the irony in this sentence. But this generalising wide-sweeping claim is an exception :)).
Google releases Chrome. A very good browser. Fast, light, efficient. But still a browser. And what do people claim? That it is the first step by Google to compete with Microsoft in the Operating System domain. That it is going very soon to replace all desktop applications! All applications will be in the 'cloud'! From the techchrunch article on Google Chrome's release:
Chrome is nothing less than a full on desktop operating system that will compete head on with Windows…Expect to see millions of web devices, even desktop web devices, in the coming years that completely strip out the Windows layer and use the browser as the only operating system the user needs.
That's just over-hyped sensationalistic journalism.
"But... ", you say, "didn't Google release an operating system recently? Won't that operating system, along with chrome make the previous claim reasonable?"
Yes. But there is one important word that makes all the difference. 'Netbooks'. For netbooks, it makes sense to have the memory and processing power in the 'cloud' and use all applications in the browser. But that doesn't mean it will be done on normal desktop systems.
In spite of what some more people say, desktop applications are here to stay. Yes, online applications are becoming popular. But only for certain things where it solves the problem better than desktop applications. Or, to put it in another way, problems that thus far had been inelegantly solved using desktop applications, are now being migrated to online applications, where it belongs. That doesn't at all mean all desktop applications will eventually run only in the 'cloud'.
I have always been a fan of desktop applications even for things for which online applications have become extremely popular. I still use my trusty old FeedDemon to check my RSS feeds. And it synchronises with Google Reader, so that I can still check my feeds on computers without FeedDemon. I use Mozilla Thunderbird to keep a copy of my mails on my computer. Just in case, you know, Gmail becomes unavailable or something. Online applications are wont to become inaccessible, go down, or just shutdown out of the blue, and there is nothing that can replace the security and safety of having your files on your own computer. Though better than that would be to have it in both places -- in the 'cloud' and on your computer.
Take, for example, Google Docs. For collaborative editing, for editing documents as a team, it is brilliant. But how many of you used Google Docs to write your thesis, or your business reports? Or to make that very important presentation? I thought so.
You might say the technology is not well developed at the moment, and it's only a matter of time blah blah blah. Nope. The fact is, for certain things online applications makes sense. For certain things it doesn't. It definitely isn't, and will never be a good solutions to each and every application requirement. That is like saying there is or will be a medicine that cures all diseases. Both of which are impossible because of the nature of the real world.
tl;dr - claiming that all applications will eventually migrate (or already have migrated) to the 'cloud' is over-hyping. Both online and desktop application have their uses.
-
Exception handling in various languages
Recently I have been doing quite a lot of thinking about error handling in various languages -- in particular exception handling. There are two major languages where I do have a bit of experience with writing large code bases -- python and java. And they take widely varying approaches to handling exceptions.
While Java has typed exceptions, and compile time checking of the typed exceptions python has unchecked exceptions. I have been thinking of the pros and cons of these, and here are my thoughts:
Checked exceptions are the bees knees when used properly. "Used properly" is the most important bit here. Checked exceptions should be thrown only for errors that are expected. Like when validation fails on user input, or a file that's supposed to exist goes for a walk through the forest of corruption. Unchecked exceptions should never ever by thrown by the code itself.
Checked exceptions are great because it serves as a great documentation of the possible erros that can happen for the given code. Of course, it's not possible for an average programmer to foresee all possible edge cases. And not all programmers are diligent enough to try.
Checked exceptions are great for use in libraries, to signal possible programming errors and bugs in the code that uses the library. For certain classes of software, it makes even more sense, if it provides a safe way to retry.
For example, writing to a database, or doing a write operation on any service. Having an idempotency key or some such to safely retry the given operation is invaluable.
The existence of unchecked exceptions, on the other hand, is completely incomprehensible and baffling. Let me be more specific here -- allowing a programmer to throw an unchecked exception in a compiled language is completely incomprehensible and baffling. The only source of untyped exceptions should be the runtime environment itself.
But in the case of interpreted languages like python, checked exceptions aren't really an option. Libraries throw arbitrary exceptions, and with bad documentation, it makes it almost impossible to write code that doesn't crash every now and then, until, by trial and error, or perusing the source code, you've figured out all the possible exceptions the library throws, and handle them appropriately. Really, that's really bad user experience. Well to be fair, having bad documentation was the real root cause here.
Enter go. It's design of exception handling is one of the most promising yet. Returning error codes with the return value, and putting the onus on the programmer to check the return value and the error code before using it can lead to pretty good code.
Take for example of a http library. If the call fails, as it inevitably will at some point, networks being what they are, you can just get back an empty return value, and the error code. Worst case when it fails for an unexpected reason, you still get back an empty return value, and a misleading error code. Seeing as it is a http library, it's not the end of the world if the call fails. An empty return value isn't going to cause that much damage since you probably already have code to handle it. Getting an unexpected exception on the other hand, that's going to crash your program, and lead to all sorts of headaches.
I mean, really, how much do you care why you get an empty result, as long as you can be sure it wasn't a bug in your program? Of all the errors you can get on a http call, only a handful are really client errors. Rest are errors you can't do anything about but retry.
Anyways, the point is that before you throw an exception, make sure you really need to throw that exception there. The other point is that, Google Go looks awesome.